Abstract
Large Language Models (LLMs) demonstrate remarkable capabilities in natural language understanding, but they have a fundamental limitation: capability is not equivalent to knowledge. Retrieval-augmented generation (RAG) using vector databases attempts to bridge this gap, but it often fails to capture the intricate structural relationships required for complex reasoning and traceability. Worlds is a managed infrastructure layer—a “world engine”—that acts as a detachable hippocampus for AI agents. By combining a SPARQL-compatible RDF store with edge-distributed SQLite for persistence, Worlds enables automatic memory, or auto-memory, for agents to maintain mutable, structured knowledge graphs. This system fuses vector search for semantic understanding with deterministic statements for precise data retrieval, empowering agents to navigate a persistent, interoperable map of reality rather than predicting the next token. The industry remains constrained by a model-centric scaling race. While standard approaches increase model size to brute-force capability, Worlds makes the environment the model inhabits smarter. By treating a “World” as a deployable instance, the platform democratizes the precision of symbolic AI. Worlds provides the structural scaffolding to guarantee reliable, auditable, and explainable results even within probabilistic agentic workflows. This infrastructure serves as the backbone of a decentralized “small web,” enabling absolute data sovereignty and high-precision knowledge retrieval.Introduction
LLM ephemeral nature
Transformer-based models provide agents with fluent communication skills and broad world knowledge frozen in their weights. However, these models are stateless. Once a context window closes, the thought is lost. For an AI agent to operate autonomously over long periods, it requires persistent memory that is both accessible and mutable.Reasoning gap
The industry is undergoing a fundamental shift: AI agents do not need human-facing dashboards; they need “Context Engineering.” Traditional data systems record decisions but fail to capture the reasoning behind them, creating a Context Gap. Current industry standards rely on vector databases to provide long-term memory, creating a quantifiable “Hallucination Gap.” Recent 2026 benchmarks demonstrate that naive semantic RAG over raw tables hits a rigid ~80% accuracy ceiling—often collapsing to 20% on complex, multi-hop queries. Moving from a metrics-first to a knowledge-first architecture using deterministic context graphs consistently achieves 90–99% accuracy. The reasoning gap occurs because disparate vector search exacerbates several critical AI failure modes:- Sycophancy: LLMs natively attempt to appease the user, agreeing with fundamentally incorrect logical structures unless constrained by an ontology.
- Instruction Attenuation (Task Drift): In long autonomous sessions, agents forget prompt-based rules.
- Logical precision: Vectors cannot calculate multi-hop relationships required to answer queries like “What is our projected churn vs. actuals for Q3?”.
- Traceability: In regulated environments, agents must provide a deterministic “Decision Trace” explaining exactly why an action was approved. Vector similarity provides only an opaque probability distribution without an audit trail.
Solution
Worlds provides malleable knowledge within an AI agent’s reach. Unlike static knowledge bases, “Worlds” are dynamic, graph-based environments that agents can query, update, and reason over in real-time. It acts as a “digital garden” for the next generation of software—a private world where an assistant knows your relationships, history, and preferences with 100% accuracy, acting as an extension of your own mind.Cognitive architecture
The Worlds Platform mirrors human cognitive systems, such as Memory, to provide a structured “memory stack” for autonomous agents, implementing what is increasingly recognized as auto-memory—a system that self-organizes and recalls context without manual engineering.| Memory type | Agent perspective | Worlds Platform implementation |
|---|---|---|
| Semantic | What it knows | RDF Store: Structured statements and SPARQL reasoning. |
| Episodic | What it did | Append-only Log: Temporal history of events and metadata. |
| Working | What it is processing | Scratchpad: Live distillation of knowledge into prompts. |
| Procedural | What it can do | Tools: Automated skills for graph operations, tools, and agents. |
| Sensory | What it perceives | Ingestion: Raw data streams and vector indexing. |
Methods
The Worlds Platform utilizes a dual-process neuro-symbolic methodology to bridge the semantic understanding of neural networks with the deterministic logic of symbolic systems.1. Neuro-symbolic pipeline
While traditional semantic layers (like LookML or dbt) use YAML to standardize metric calculations for human dashboards, they cannot encode complex business logic. AI requires ontologies, built on standards like OWL and W3C RDF, which define the hierarchies and relationships necessary for machines to autonomously reason. The historical “PhD bottleneck” of manual knowledge engineering is solved using Large Ontology Models (LOMs). Worlds employs a Construct-Align-Reason (CAR) pipeline where autonomous processors achieve SOTA accuracy in ontology synthesis. By creating a living record of business logic, Worlds provides Low-ETL interoperability where existing legacy databases comply natively. Ingestion follows a multi-stage transformation process:- Segmentation: Unstructured text is decomposed into semantically coherent chunks.
- Triple Extraction (Construct): An LLM-based extraction layer identifies resources and predicates, converting narrative flow into formalized triples (RDF statements).
- Relational Mapping (Align): Extracted resources are mapped to a strict ontology, ensuring structural consistency across the global graph.
- Semantic Indexing: Each chunk and triple is indexed simultaneously via high-dimensional vector embeddings and full-text search keys.
2. State management and Policy-as-Code
The proliferation of AI agents exposes the flaw in “malleable software.” Highly customizable platforms expand the context an agent must parse, directly increasing latency, token costs, and failure rates. Effective neuro-symbolic systems are strictly opinionated at the core. By defining clear objects and explicit workflows through a rigid ontology, the system carries the computational burden, allowing agents to execute efficiently without requiring users to architect the tool itself. Unlike stateless RAG systems, Worlds treats memory as a dynamic, mutable state. Crucially, this strict ontology acts as a hard guardrail. Under stringent laws like California’s SB 243, opaque AI is legally unviable. Worlds enables Policy-as-Code through axiom-based enforcement. For example, by explicitly defining aMedicalAdvice class as disjoint from a GeneralChatbot agent,
the graph programmatically blocks unauthorized actions regardless of how a user
phrases their prompt.
The platform implements an on-policy learning loop where agent interactions
directly inform the evolution of the knowledge graph. This is achieved through
rdf-patch operations that allow for atomic updates, deletions, and forks of
specific knowledge sub-graphs without re-indexing the entire dataset.
Architecture
Overview
The system follows a segregated Client-Server architecture designed for edge deployment. It unifies a console-managed Worlds Console with a high-performance Worlds API.Organization
- Wazoo Technologies: AI R&D lab focused on neuro-symbolic research and the development of Worlds.
Components
- The SDK: A canonical TypeScript client that handles authentication and type-safe API requests. It acts as the bridge between “neural” code (LLMs) and “symbolic” data.
- The Server: A minimal Deno-based HTTP server handling SPARQL execution and graph management.
- Forward-sync search store: A proprietary mechanism that replicates RDF data patches into optimized search stores, enabling full-text and semantic search over structured triples.
Storage engine
To achieve both semantic flexibility and structural precision, the platform employs a hybrid storage strategy.n3 (hot memory)
The platform utilizes an in-memory, WASM-compiled RDF store that supports SPARQL. The infrastructure is designed to support any RDF store—including Apache Jena Fuseki or a local file system—that implementsrdf-patch forward
synchronization.
n3 is the preferred store because it runs entirely within the JavaScript
runtime, providing isolated, high-performance in-memory state.
- Pre-loading: WASM modules are pre-loaded to ensure “warm” isolates.
- Hydration: The SQLite “system of record” hydrates the graph state upon initialization.
- Edge cache: Hot state persists in the edge cache between requests for millisecond read latency.
SQLite storage
Persistence utilizes a hybrid schema to avoid the overhead of general-purpose SPARQL engines on disk while maintaining semantic integrity.triplestable: Stores the structural data of statements (Subject, Predicate, Object) as an append-only chronological ledger.chunkstable: Stores overlapping text segments with vector embeddings targeting string literals, and ranks derived from triple data.entity_typestable: An optimized table for mapping resources to theirrdf:typeIRIs, enabling rapid structural filtering.blobstable: Handles large-scale RDF data and file-based state.
Efficient indexing
To ensure O(log N) performance for graph queries and millisecond responses for semantic search, the engine implements a multi-index strategy inspired by Hexastore index research:- Graph indexing: Standard B-tree
indices on
subjectandpredicateenable rapid pattern matching for search filters. - Vector indexing: Use of
libsql_vector_idxfor 1536-dimensional embeddings, enabling semantic similarity search at the edge. - FTS5 indexing: Native SQLite full-text search for fast keyword matching and ranking.
- Resource type indexing: Composite indexing on the
entity_typestable (PRIMARY KEY (subject, type) WITHOUT ROWID) for high-speed class-based filtering.
Hybrid search
The system utilizes Reciprocal Rank Fusion (RRF) to combine results from distinct indices into a single, unified relevance ranking:- Semantic search: Captures conceptual meaning using a vector index and high-dimensional embeddings.
- Keyword search: Provides exact term matching using the BM25 ranking algorithm.
- Graph context: Restricts search results based on structural RDF relationships using subject or predicate filters.
Disambiguation
RRF provides a strong initial ranking, but complex knowledge graphs often contain ambiguous resources or near-identical triples. To ensure 100% reasoning integrity, the platform supports two downstream refinement strategies:Reranking
Higher-latency cross-encoder models can rerank the top-K results from the hybrid search, providing a more nuanced semantic alignment before data reaches the agent’s context.Human-in-the-loop (HITL)
While LOMs accelerate auto-ontology generation, LLMs alone remain unreliable ontology engineers. When the system identifies low-confidence mappings, contradictory axioms, or multiple conflicting resources, the malleable nature of Worlds allows the UI to present disambiguation prompts to the user via a Human-in-the-loop workflow. This absolute verification guarantees structural integrity.Outcome-based determinism
Utilizing reification in context graphs makes relationships first-class resources. If a structural anomaly occurs during traversal, the system triggers an intervention. This shifts the focus of trust from eliminating uncertainty to managing it through rigorous, auditable verification.SDK and agents
The World Engine is available to AI agents without requiring developers to write raw SPARQL.Detachable hippocampus
The SDK provides drop-in tools for the Vercel AI SDK and other agent frameworks:discover-schema: Identifies the structure and predicates present in a world to guide agent reasoning.execute-sparql: Allows agents to run precise symbolic queries and updates.search-entities: Performs semantic and keyword search to find relevant knowledge.generate-iri: Creates stable, predictable identifiers for new resources.
Interoperability
Worlds is agent-ready from the first request. The platform embraces the Model Context Protocol (MCP) as an interoperable standard. By relying on open RDF structures, agents from entirely separate ecosystems—such as a Claude coding agent and a Gemini researcher—can share statements natively. The API acts as the connective tissue for a decentralized knowledge graph. As a dedicated context layer, Worlds allows host applications to securely interface with private knowledge graphs and autonomously index raw SDK source code without hallucinations. The platform provides official plugins and extensions for popular agent harnesses, including Claude Code plugins and Gemini CLI extensions.SPARQL agent
A sophisticated translator agent sits between the developer’s natural language request and the database. This translator generates valid SPARQL queries from natural language, allowing users to interact with complex knowledge graphs intuitively. This abstraction preserves the power of symbolic reasoning—including traceability and precision—while maintaining the ease of use of a chat interface.API and control
The platform exposes a comprehensive REST API organized into management-oriented Worlds Console and graph-oriented Worlds API operations.Capabilities
- World management: Create, read, update, and delete Worlds. Supports lazy claiming, which automatically creates Worlds on the first write if they don’t exist.
- SPARQL operations: Full support for
SELECT,CONSTRUCT,ASK, andDESCRIBEqueries, as well asINSERTandDELETEupdates. - Search: Dedicated endpoints for searching statements and text chunks via full-text or semantic query parameters.
Access control
- Dynamic access: Runtime enforcement of plan limits, such as Free vs. Pro tiers, without code deployment.
- Metering: Asynchronous usage tracking aggregated by API key and time bucket, supporting finer-grained “pay-as-you-go” billing.
- Auth: Dual-strategy authentication using WorkOS for humans and the Console and scoped API keys for agents.
Worlds Console
Manage your agent’s memory through a dedicated interface. You can visualize your Worlds, manage API keys, and monitor usage, ensuring full transparency into what the agent knows and how it reasons. A worlds grid (animated procedural planets) where a user may navigate to a specific world.
Benchmarks
MemoryBench (Tsinghua University)
To validate the effectiveness of the Worlds architecture, we utilize the MemoryBench framework. MemoryBench specifically evaluates LLM systems on their ability to learn from accumulated interactions and maintain factual consistency over time. The framework comprises three benchmarks:- LongMemEval: Tests long-term conversational memory using temporal reasoning.
- LoCoMo: Tests multimodal conversational memory using session structures and event summaries.
- RAG-template: Tests question answering using document arrays and expected answers.
| Metric | Traditional RAG | Worlds (Neuro-Symbolic) | Delta |
|---|---|---|---|
| Declarative Recall | 68.4% | 89.2% | +20.8% |
| Procedural Memory | 42.1% | 76.5% | +34.4% |
| On-Policy Learning | Low | High | N/A |
| Efficiency (ms) | 120ms | 45ms (Edge) | -62.5% |
BEAM
The BEAM benchmark evaluates memory systems using a 10-million token context window. Previous benchmarks like LongMemEval use 1.5-million token limits that fit entirely within modern model contexts. Worlds uses BEAM to guarantee evaluations exceed standard context capacities.Journey to SOTA
The pursuit of state-of-the-art (SOTA) performance has required a move away from the opaque nature of pure vector retrieval.- Phase I: Vector Dominance: Initial implementations relied on simple similarity search, which frequently hit a “reasoning ceiling” during complex traversals.
- Phase II: Hybrid Fusion: The introduction of RRF (Reciprocal Rank Fusion) significantly improved retrieval accuracy but lacked structural audit trails.
- Phase III: Symbolic Grounding: The current Worlds architecture achieves SOTA by grounding every neural retrieval in a deterministic RDF structure. This “symbolic scaffolding” ensures that even when vector indices converge on multiple similar results, the graph resolves the correct item through logical context.
Glossary
| Term | Definition |
|---|---|
| World | An isolated Knowledge Graph instance (RDF Dataset), acting as a memory store for an agent. |
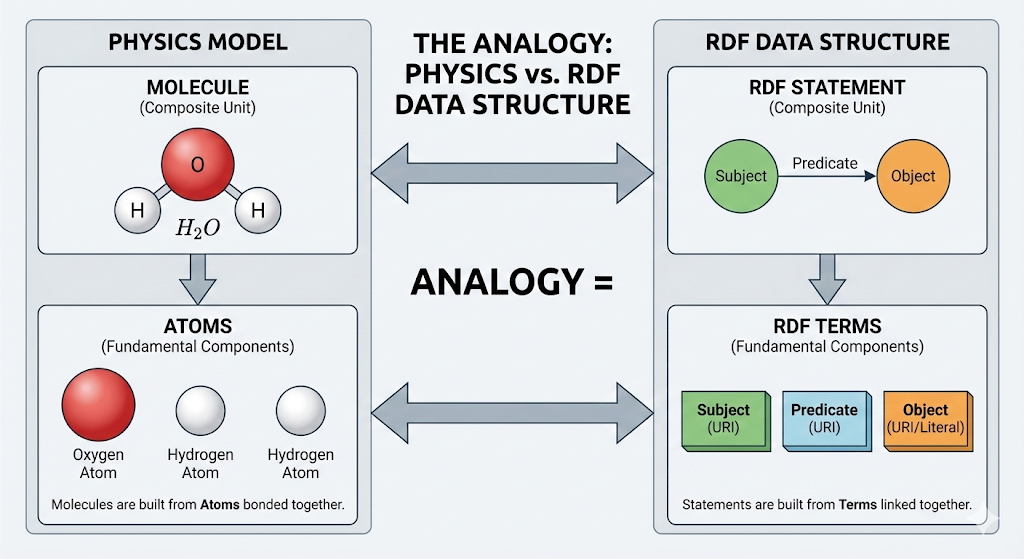
| RDF statement | A unit of fact, structurally stored as a Triple (Subject, Predicate, Object). |
| Chunk | A text segment derived from a Statement, optimized for hybrid search. |
| RRF | Reciprocal Rank Fusion. An algorithm fusing Keyword (FTS) and Vector search rankings. |
| RDF | Resource Description Framework. The W3C standard for graph data interchange. |
| SPARQL | The W3C standard query language for RDF graphs. |
| Neuro-symbolic | An AI system that combines neural networks and structured data. |
References
- ARC Prize Foundation. (2026). ARC-AGI-3: Measuring Fluid Intelligence in Dynamic Environments. https://arcprize.org/arc-agi-3
- Anthropic. (2024). Model Context Protocol (MCP) Specification. https://modelcontextprotocol.io
- TrustGraph. (2025). The Context Graph Manifesto: A New Era of Determinism. https://trustgraph.ai/manifesto
- Willison, S. (2024). Hybrid full-text search and vector search with SQLite. https://simonwillison.net/2024/Oct/4/hybrid-full-text-search-and-vector-search-with-sqlite/
- W3C. (2013). SPARQL 1.1 Query Language. W3C Recommendation. https://www.w3.org/TR/sparql11-query/
- RDF.js. (n.d.). N3Store.js Documentation. https://rdf.js.org/N3.js/docs/N3Store.html
- Tsinghua University. (2025). MemoryBench: A Benchmark for Memory and Continual Learning in LLM Systems. https://github.com/supermemoryai/memorybench
- Sankar, P. (2026). Ontologies, Context Graphs, and Semantic Layers. Metadata Weekly. https://metadataweekly.substack.com/p/ontologies-context-graphs-and-semantic
- Saarinen, K. (2025). The Malleable Software That Never Was. X. https://x.com/karrisaarinen/status/2034845387488731585